Долгое время мы активно использовали только один стек для приема метрик - на базе graphite (carbon-c-relay, carbon-clickhouse, graphite-clickhouse, clickhouse). Что это за стек, можно посмотреть в другой статье (https://linux96.ru/index.php/30-graphite-based-monitoring) и гитхаб страницах проектов. Все бы ничего, но новый софт почти по дефолту выставляет свои метрики в формате для прометея и чтобы получать метрики софта, в наличии есть только экспортеры. Прометей - это почти дефолт в мире мониторинга (как ansible в мире IaC), cнимать метрики хочется, но слазить с graphite стека очень трудно и времязатратно. Что можно придумать?
Во-первых, сначала опишем первичные (очень приблизительные) требования к нашей обновленной системе мониторинга на базе prometheus:
- предположительно будет много метрик
- метрики будем хранить несколько лет (2-5)
- хотим максимально использовать текущие знания/инфраструктуру
Для разовой задачи можно использовать типа такого - https://linux96.ru/index.php/35-metriki-iz-prometheus-v-graphite, но это решение совсем не масштабируемо и может лишь отчасти подходить, если надо что-то разово замониторить.
По дефолту пром пишет в Local Storаge, начинаем читать доку:
limitation of local storage is that it is not clustered or replicated.
Prometheus's local storage is not intended to be durable long-term storage; external solutions offer exteded retention and data durability.
Alternatively, external storage may be used via the remote read/write APIs.
Хорошо, идем в доку https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage и смотрим, что там есть. Некоторые консультации в одном из телеграм чатов дают картину о том, что в кач-ве long term storage (lts) активно берут victoria metrics, далее по убыванию thanos и т.д. Там же в чате подсказывают, что можно остаться на текущем стеке carbon-CH, graphite-CH, где уже есть интеграция с prometheus. Ok, это очень хорошие новости, идем на гитхаб страницы проектов, гуглим и сталкиваемся с тем, что в интернете просто отсутствует информация как это реализовать (а документация этих проектов на гитхабе ооочень скупа). Хотя сама идея использовать clickhouse как lts для прома выглядит очень вкусно. Что ж, это статья призвана восполнить текущий недостаток информации по организации данного стека.
Вообще, видимо, есть много вариантов как вообще собрать данный конструктор:
- carbon-CH может работать remote_write для Prometheus
- graphite-CH может работать remote_read для Prometheus
- carbonapi может работать remote_read для Prometheus (не тестировал, сугубо по чужой инфорации)
Чтобы начать приводить листинги конфигов, предварительно обрисуем на верхнем уровне планируемую связку по мониторингу:
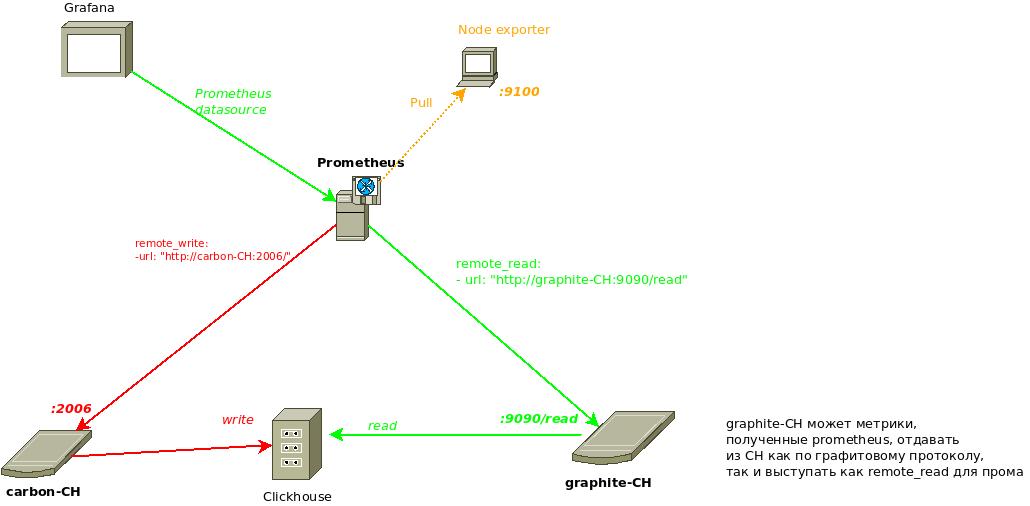
Т.е. всё довольно просто: через remote_write пушим метрики в carbon-CH, который услужливо их будет класть в таблицы clickhouse. Строить дашборды в графане будем через Prometheus datasource (чтобы загрузить метрики, пром через remote_read их будет запрашивать у graphite-CH, а graphite-CH будет "смотреть" в те же таблицы, в которые пишет carbon-CH). В данную схему можно добавить репликацию на уровне CH, тем самым повысив отказоустойчивость и распределив нагрузку с хостов баз данных (carbon-CH пишет в таблицы бд CH_1, они реплицируется в другую бд CH_2, graphite_CH читает с бд CH_2 ).
Чтобы всё заработало, carbon-CH должен писать в 3 типа таблиц (point table, index table, tagged table), а graphite-CH - соответственно читать из 3-х типов таблиц (data-table, index-table, tagged-table). На этом моменте возникла сначала некоторая загвоздка, т.к. ранее в других инстансах carbon-CH и graphite-CH мы особо не использовали таблицу с типом tagged, которая являлась опциональной (она нужна для использования фунционала Graphite tag при использовании datasource c типом Graphite в Grafana), поэтому, чтобы prometheus мог использовать указанный remote_read, все 3 типа таблиц обязательны.
По идее, когда метрики от carbon-CH попадут в хранилище на CH, можно остаться на старом-добром Graphite datasource в графане - через связку grafana - carbonapi - graphite-CH, но это неудобно тем, что не получиться импортировать готовые дашборды с grafana.com c Prometheus datasource. В текущей предложенной схеме graphite-CH и carbon-CH скроют под собой как оно там работает, снаружи будем взаимодействовать с обычным прометеусом.
Приведем листинги всех микросервисов, из которых уже более внятно сложится как это работает.
1. Конфиг прометея
prometheus.yml:
global:
scrape_interval: 60s
scrape_configs:
- job_name: some-job
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- some-target:80
remote_write:
- url: "http://carbon-ch:2006"
remote_read:
- url: "http://graphite-ch:9090/read"
В прометее не забываем правильно указывать правильный endpoint для remote_read (данный endpoint будет обслуживать graphite-CH)
2. Конфиг carbon-CH
[common]
metric-prefix = "stats.carbon_clickhouse.prom.{host}"
metric-endpoint = "local"
max-cpu = 1
metric-interval = "1m0s"
[data]
path = "/data/carbon-clickhouse/"
compression-level = 0
chunk-interval = "30s"
chunk-auto-interval = ""
compression = "none"
[upload.graphite]
type = "points"
table = "some-database.table-points"
zero-timestamp = false
threads = 1
url = "http://user:password\@clickhouse-host.ru:8123/?max_query_size=268435456&max_ast_elements=1000000"
timeout = "1m0s"
[upload.graphite_index]
type = "index"
table = "some-database.table-index"
threads = 1
url = "http://user:password\@clickhouse-host.ru:8123/?max_query_size=268435456&max_ast_elements=1000000"
timeout = "1m0s"
cache-ttl = "12h0m0s"
[upload.graphite_tagged]
type = "tagged"
table = "some-database.table-tagged"
threads = 1
url = "http://user:password\@clickhouse-host.ru:8123/?max_query_size=268435456&max_ast_elements=1000000"
timeout = "1m0s"
cache-ttl = "12h0m0s"
[udp]
listen = ":2003"
enabled = false
log-incomplete = false
drop-future = "0s"
drop-past = "0s"
[tcp]
listen = ":2003"
enabled = false
drop-future = "0s"
drop-past = "0s"
[pickle]
listen = ":2004"
enabled = false
[prometheus]
listen = ":2006"
enabled = true
drop-future = "0s"
drop-past = "0s"
[[logging]]
logger = ""
file = "/var/log/carbon-clickhouse.log"
level = "info"
encoding = "mixed"
encoding-time = "iso8601"
encoding-duration = "seconds"
[convert_to_tagged]
enabled = false
separator = ""
Порты 2003 и 2004 отключаем, иначе они по дефолту будут включаться, если даже в конфиге нигде не прописаны. Включаем 2006 порт, на котором будем по remote_write протоколу от прома принимать метрики. Намеренно не привожу sql команды для создания таблиц в CH, это есть в доках микросервисов (или в ссылке из начала данной статьи).
3. Конфиг graphite-CH
[common] listen = ":9090" max-cpu = 1 max-metrics-in-find-answer = 0 [clickhouse] url = "http://user-password\@clickhouse-host.ru:8123/?max_query_size=268435456&max_ast_elements=1000000" extra-prefix = "" data-table = "some-database.table-points" data-timeout = "1m0s" index-table = "some-database.table-index" index-use-daily = true index-timeout = "1m" tagged-table = "some-database.table-tagged" date-tree-table = "" date-tree-table-version = 0 tree-timeout = "1m0s" [[logging]] logger = "" file = "/var/log/graphite-clickhouse/graphite-clickhouse.log" level = "info" encoding = "mixed" encoding-time = "iso8601" encoding-duration = "seconds"
graphite-CH запускает на своем порту оболочку от прометея, в котором можно поделать запросы как бы в прометей (т.е. заходим по http в graphite-CH и видим там веб-интерфейс прома, можно писать Promql запросы, которые прозрачно будут трансформироваться в sql запросы в CH).
Далее в Grafana подключаем новый datasource с типом Prometheus, указываем адрес прометей сервера (не graphite-CH).
Чем на данный момент эта схема для нас оказалась удобна - минимальное время на внедрение, т.к. все основные микросервисы уже есть (дело за разворачиванием новых инстансов carbon-CH и graphite-CH ), пара clickhouse серверов уже тоже есть, создаем базу и реплицированные таблицы. В общем весь стек почти знаком, можно сразу ставить нужные экспортеры и импортировать готовые дашборды. Указанная связка, конечно, не очень распространена, в отличии от victoria metrics как long term storage, но в будущем, при такой схеме особо ничего не мешает ее добавить как remote_write. Пока первичные тесты прошли успешно - внедрил тройку экспортеров, всё завелось сразу, не пришлось пока "лазить под капот" (т.е. типичный flow - настроил экспортер, проверил метрики в прометее, импортировал дашборд - всё на этом).
Вполне возможно, что статья будет дополняться по прошествии получения дальнейшего опыта эксплуатации данного стека.