Есть 2 подхода для съема метрик - pull (яркий представитель - prometheus) и push (яркий представитель - graphite). Graphite - это мониторинг, состоящий из целой пачки различных микросервисов, некоторые уже почили в бозе, некоторые еще живы. Я по приходу в компанию, где сейчас работаю, застал такую расстановку сил: brubeck (для агрегации метрик), go-carbon ( занимается тем, что принимает метрики от всех и отдаёт их carbonapi), carbonapi (демон отдаёт метрики клиентам (в частности grafana)).
Несколько слов чем оказалась привлекательна новая схема и чем не устраивала старая (на основе go-carbon):
- go-carbon - много пишет на диск, на текущих нагрузках мощностей SATA-дисков не хватило => перешли на SSD, которые дороже и имеют меньшие объемы
- у нас go-carbon резервирует глубину хранения метрик до 10 лет, каждый wsp-файл занимает 512Кб => вечный недостаток места на SSD (wsp файлов порядка 1млн)
- использование стека, основанного на clickhouse, позволяет использовать недорогие и объемные SATA-диски + плюс сами возможности БД (репликация и т.п.)
- graphite-clickhouse с новой версией carbonapi позволяет использовать tag (labels в терминологии prometheus)
- хотелось прикрутить систему алертинга moira (хотя по-честному, go-carbon этому не мешал, т.к. достаточно просто поместить его за carbon-c-relay)
За основу взяли эту статью - https://habr.com/ru/company/avito/blog/343928/ (статья от 2017 года, но мы у себя к подобной схеме перебрались только сейчас). У нас прием метрик на порядок меньше (200тыс/мин, т.е. чуть более 3-х тыс/сек), поэтому наша схема проще и скорей всего может подойти большинству.
В интернете достаточно и статей и схем как связаны между собой микросервисы, в выше указанной ссылке они тоже есть. Ниже приведу более простую схему и листинг конфигов.
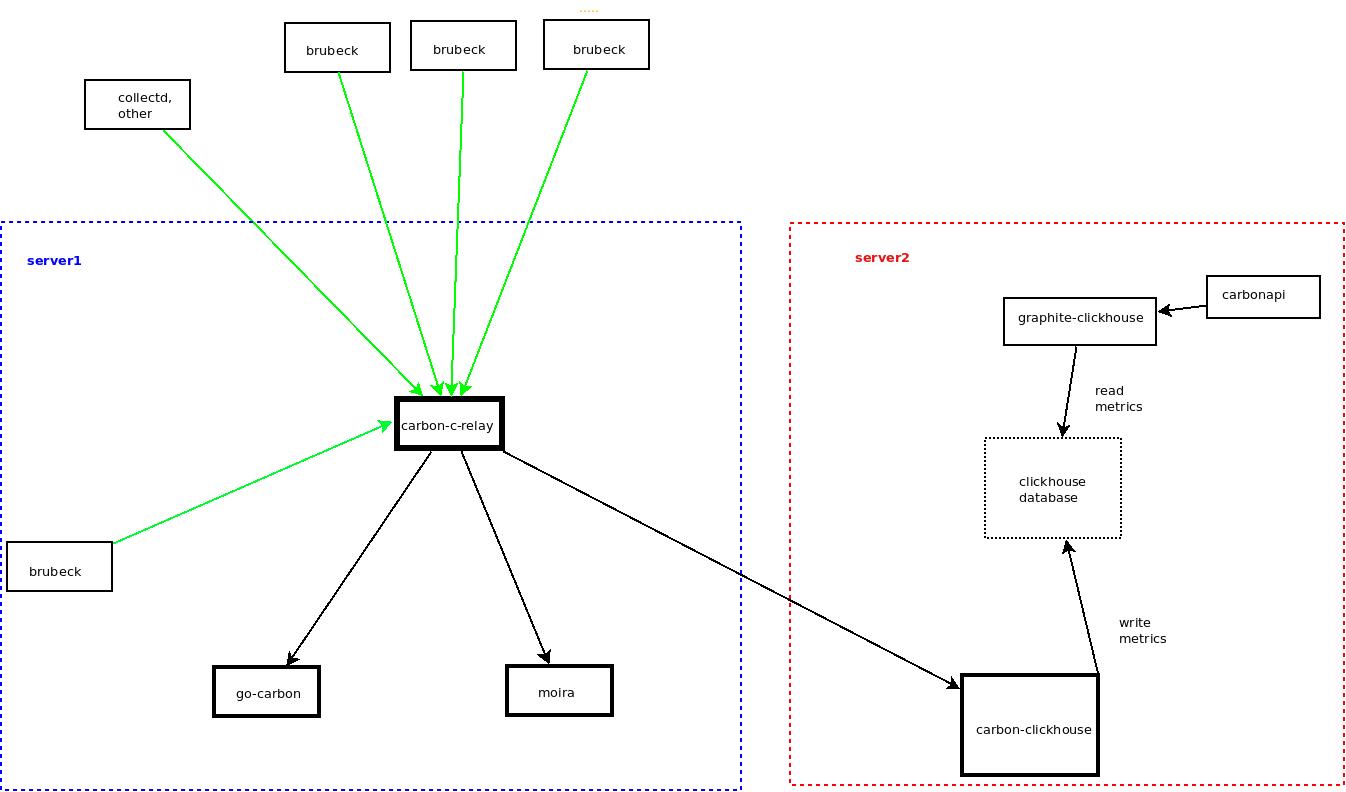
1) Collectd, brubeck, скрипты пушат свои метрики в роутер метрик - carbon-c-relay (https://github.com/grobian/carbon-c-relay). Он принимает на себя весь поток метрик и далее перенаправляет на сервера бэкендов метрик.
Что дает его использование в нашем случае - возможность фильровать метрики на самом входе, безболезненное добавление новых приемников метрик.
2) moira - сервис алертинга https://github.com/moira-alert/moira. Принимает на себя весь тот же поток метрик, что и другие бэкенды, но сразу фильтрует (т.е. принимает только те метрики, которые прописаны в триггерах).
Что она дает - можно оперативно добавлять свои алерты, используя встроенные функции графита; новый хост, который отправляет свои метрики, на которые в свою очередь "навешан" триггер в moira, сразу начинает мониториться.
3) стек приема метрик, включающий их запись и чтение из clickhouse:
- carbon-clickhouse https://github.com/lomik/carbon-clickhouse: получает метрики, буферизует и с некоторой периодичностью отправляет их в БД
- clickhouse database
- graphite-clickhouse https://github.com/lomik/graphite-clickhouse: бэкенд для чтения метрик из clickhouse. В grafana для подключения нового datasource использует carbonapi, который в свою очередь обращается к graphite-clickhouse)
Конфиги сервисов:
1. Конфиг carbon-c-relay.conf:
cluster graphite
fnv1a_ch replication 3
go-carbon-server:3003
carbon-clickhouse-server:3003
moira-server:3003
;
match *
send to graphite
;
listen type linemode
2003 proto udp
2003 proto tcp
;
statistics
submit every 60 seconds
prefix with stats.server.carbon_c_relay
send to
graphite
;
2. Конфиг carbon-clickhouse.conf:
[common]
metric-prefix = "stats.{host}.carbon_clickhouse"
metric-endpoint = "local"
max-cpu = 1
metric-interval = "1m0s"
[data]
path = "/data/carbon-clickhouse/"
compression-level = 0
chunk-interval = "30s"
chunk-auto-interval = ""
compression = "none"
[upload.graphite]
type = "points"
table = "graphite.graphite"
zero-timestamp = false
threads = 1
url = "http://user:PASSW@server:8123/?max_query_size=268435456&max_ast_elements=1000000"
timeout = "1m0s"
[upload.graphite_index]
type = "index"
table = "graphite.graphite_index"
threads = 1
url = "http://user:PASSW@server:8123/?max_query_size=268435456&max_ast_elements=1000000"
timeout = "1m0s"
cache-ttl = "12h0m0s"
[upload.graphite_tagged]
type = "tagged"
table = "graphite.graphite_tagged"
threads = 1
url = "http://user:PASSW@server:8123/?max_query_size=268435456&max_ast_elements=1000000"
timeout = "1m0s"
cache-ttl = "12h0m0s"
[udp]
listen = ":2003"
enabled = true
log-incomplete = false
drop-future = "0s"
drop-past = "0s"
[tcp]
listen = ":2003"
enabled = true
drop-future = "0s"
drop-past = "0s"
[[logging]]
logger = ""
file = "/var/log/carbon-clickhouse.log"
level = "info"
encoding = "mixed"
encoding-time = "iso8601"
encoding-duration = "seconds"
[convert_to_tagged]
enabled = false
separator = ""
Единственно что крутили - увеличили chunk-interval с 1 до 30 сек (при 1-ой сек clickhouse через некоторое время начал писать о том, что
DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts.
), max_query_size и max_ast_elements.
graphite.graphite, graphite.graphite_index, graphite.graphite_tagged - метрики пишутся в БД graphite и соответствующие таблицы (иначе будут попадать в дефолтную БД - default)
3. Конфиг graphite-clickhouse.conf:
[common] listen = ":9090" max-cpu = 1 max-metrics-in-find-answer = 0 [clickhouse] url = "http://user:PASSW@clickhouse-server:8123/?max_query_size=268435456&max_ast_elements=1000000" extra-prefix = "" data-table = "graphite.graphite" data-timeout = "1m0s" index-table = "graphite.graphite_index" index-use-daily = true index-timeout = "1m" tagged-table = "graphite.graphite_tagged" date-tree-table = "" date-tree-table-version = 0 tree-timeout = "1m0s" [[logging]] logger = "" file = "/var/log/graphite-clickhouse/graphite-clickhouse.log" level = "info" encoding = "mixed" encoding-time = "iso8601" encoding-duration = "seconds"
4. Факультативно привожу схему таблиц clickhouse (опции были подсказаны местными программистами, активно использующими clickhouse, ничего не мешает взять схему, которая указана на гитхабе)
CREATE TABLE graphite.graphite (`Path` String CODEC(ZSTD(16)), `Value` Float64 CODEC(Gorilla, ZSTD(16)), `Time` UInt32 CODEC(DoubleDelta), `Date` Date CODEC(DoubleDelta, LZ4HC(9)), `Timestamp` UInt32 CODEC(DoubleDelta)) ENGINE = ReplicatedMergeTree('/clickhouse/tables/graphite.graphite', '{hostname}') PARTITION BY toStartOfWeek(Date) PRIMARY KEY (Path, round(Time, -5)) ORDER BY (Path, round(Time, -5), Time) SETTINGS index_granularity = 8192, enable_mixed_granularity_parts = 1
CREATE TABLE graphite.graphite_index (`Date` Date, `Level` UInt32, `Path` String, `Version` UInt32) ENGINE = ReplicatedMergeTree('/clickhouse/tables/graphite.graphite_index', '{hostname}') PARTITION BY toYYYYMM(Date) ORDER BY (Level, Path, Date) SETTINGS index_granularity = 8192, enable_mixed_granularity_parts = 1
CREATE TABLE graphite.graphite_tagged (`Date` Date, `Tag1` String, `Path` String, `Tags` Array(String), `Version` UInt32) ENGINE = ReplicatedMergeTree('/clickhouse/tables/graphite.graphite_tagged', '{hostname}') PARTITION BY toYYYYMM(Date) ORDER BY (Tag1, Path, Date) SETTINGS index_granularity = 8192
В основном стремились задействовать кодек, который будет максимально сжимать столбцы + нужна была репликация
Добавлю сюда также то, как мне популярным образом объяснили как настраивается репликация в Clickhouse:
1) создаешь в базе Х на сервере Y таблицу Z (реплицируемую) - у тебя данные пишутся только туда, никто ничего никуда не реплицирует 2) создаешь в базе AAA на сервере Y таблицу Z1 с таким же путем в zookeper - теперь на сервере Y две одинаковые таблицы с разными именами, но одинаковыми данными 3) создаешь в базе BBB на сервере C таблицу Z2 с таким же путем в zookeper - теперь все три таблицы между собой реплицируются, можно писать и читать в любую и с любой Соответственно для репликации надо иметь 2 таблицы с одинаковой структурой (названия не важны), у которых будет 1 путь в zookeeper и он сам сразу все отреплицирует и синхронизирует
5. Конфиг carbonapi.yaml
cat /etc/carbonapi/carbonapi.yaml cache: type: 'null' concurency: 20 cpus: 1 graphite: host: carbon-c-relay:2003 interval: 60s prefix: stats.carbonapi-cerver.carbonapi idleConnections: 10 listen: 0.0.0.0:7081 logger: - encoding: console file: /home/carbonapi/logs/carbonapi.log level: info logger: '' maxBatchSize: 100 pidFile: '' sendGlobsAsIs: true tz: '' zipper: http://127.0.0.1:9090
Кратко о том, как можно начать пользоваться тегами:
https://graphite.readthedocs.io/en/latest/tags.html
- отправляем метрики с тегами:
echo "host444.df.var.df.complex.free;disk=var;type=free `shuf -i1-10 -n1` `date +%s`" | nc -C -t -q 0 -N SERVER 2003 echo "host333.df.root.df.complex.free;disk=root;type=free `shuf -i1-10 -n1` `date +%s`" | nc -C -t -q 0 -N SERVER 2003 echo "host4.load.longterm;env=prod;location=russia `shuf -i1-10 -n1` `date +%s`" | nc -C -t -q 0 -N SERVER 2003
В самой базе clickhouse соответствующая таблица будет иметь примерно следующее содержимое:SELECT * FROM graphite_tagged ┌───────Date─┬─Tag1─────────────────────────────────────┬─Path────────────────────────────────────────────────┬─Tags─────────────────────────────────────────────────────────────────┬────Version─┐ │ 2019-11-19 │ __name__=host123.df.root.df.complex.used │ host123.df.root.df.complex.used?disk=root │ ['__name__=host123.df.root.df.complex.used','disk=root'] │ 1574141308 │ │ 2019-11-19 │ __name__=host123.df.root.df.complex.used │ host123.df.root.df.complex.used?disk=root&type=used │ ['__name__=host123.df.root.df.complex.used','type=used','disk=root'] │ 1574140068 │ │ 2019-11-19 │ __name__=host123.df.root.df.complex.used │ host123.df.root.df.complex.used?disk=root&type=used │ ['__name__=host123.df.root.df.complex.used','disk=root','type=used'] │ 1574140888 │ │ 2019-11-19 │ disk=root │ host123.df.root.df.complex.used?disk=root │ ['__name__=host123.df.root.df.complex.used','disk=root'] │ 1574141308 │ │ 2019-11-19 │ disk=root │ host123.df.root.df.complex.used?disk=root&type=used │ ['__name__=host123.df.root.df.complex.used','type=used','disk=root'] │ 1574140068 │ │ 2019-11-19 │ disk=root │ host123.df.root.df.complex.used?disk=root&type=used │ ['__name__=host123.df.root.df.complex.used','disk=root','type=used'] │ 1574140888 │ │ 2019-11-19 │ type=used │ host123.df.root.df.complex.used?disk=root&type=used │ ['__name__=host123.df.root.df.complex.used','type=used','disk=root'] │ 1574140068 │ │ 2019-11-19 │ type=used │ host123.df.root.df.complex.used?disk=root&type=used │ ['__name__=host123.df.root.df.complex.used','disk=root','type=used'] │ 1574140888 │ └────────────┴──────────────────────────────────────────┴─────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────┴────────────┘ ┌───────Date─┬─Tag1──────────────────────────────────────┬─Path─────────────────────────────────────────────────┬─Tags──────────────────────────────────────────────────────────────────┬────Version─┐ │ 2018-04-24 │ __name__=host5555.df.root.df.complex.used │ host5555.df.root.df.complex.used?disk=root&type=used │ ['__name__=host5555.df.root.df.complex.used','disk=root','type=used'] │ 1570174122 │ │ 2018-04-24 │ disk=root │ host5555.df.root.df.complex.used?disk=root&type=used │ ['__name__=host5555.df.root.df.complex.used','disk=root','type=used'] │ 1570174122 │ │ 2018-04-24 │ type=used │ host5555.df.root.df.complex.used?disk=root&type=used │ ['__name__=host5555.df.root.df.complex.used','disk=root','type=used'] │ 1570174122 │ └────────────┴───────────────────────────────────────────┴──────────────────────────────────────────────────────┴───────────────────────────────────────────────────────────────────────┴────────────┘
- можно теги и их значения посмотреть в графане - https://grafana.com/docs/features/datasources/graphite/#templating
Например, добавить переменные, где в качестве Query может быть следующее:Query: tags() Query: tag_values(disk)
- Чтобы воспользоваться тегами при создании графиков, пишем примерно так:
в Series сразу указываем
seriesByTag('location=russia') - Глянуть теги напрямую из graphite-clickhouse:
curl -s "http://some-host:some-port/tags/autoComplete/tags?limit=1000"
В чем может быть удобство использования тегов? Нет необходимости помнить/вводить длинную серию в grafana, достаточно указать tag и она сама все отобразит на графике.
Теги конечно здесь выглядят, как по мне, по-инопланетянски. В этом плане prometheus удобней - там использование labels является базовой вещью, которую проектировали изначально.