Для чего может быть понадобится делать столь странные вещи? Например, одной из причин может быть использование стека приема метрик на базе graphite (т.е. push метрик вместо pull). Это конечно, менее молодежно, чем prometheus, но все равно имеет право на жизнь :). В нашем случае может существовать некий софт, который заточен отдавать свои метрики для prometheus. Мне, в частности, встретился такой на пути - minio (https://github.com/minio/minio). Вот и будем рассматривать на его примере.
Почему просто не поднять prometheus и жить с двумя системами мониторинга? Мой ответ: тогда prometheus надо бекапить(метрики), настраивать свою систему алертинга, в графане использовать еще один datasource. Зачем это делать, если уже все это реализовано в своем стеке? Можно prometheus использовать просто как некий переходник. Для решения данной задачи могут подойти 2 продукта:
- graphite-remote-adapter (https://github.com/criteo/graphite-remote-adapter)
- telegraf - не проверял, но говорят у него можно использовать prometheus как input, а graphite - как output.
Будем пробовать первый софт из списка. Схему взаимодействия можно изобразить таким образом:
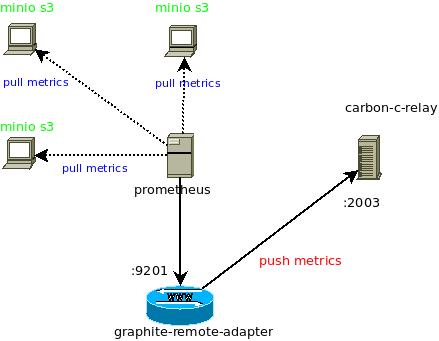
Minio имеет исчерпывающее руководство как настроить мониторинг через prometheus.
Конфиг prometheus.yml может принять следующий вид:
global:
scrape_interval: 15s
scrape_configs:
- job_name: minio-job_myserver_8080
bearer_token: eyJhbG....fSyNg
metrics_path: /minio/prometheus/metrics
scheme: http
static_configs:
- targets: ['myserver.test.ru:8080']
relabel_configs:
- source_labels: [__address__]
target_label: instance
regex: '(.*)\..*\..*:(.*)'
action: replace
replacement: '${1}_${2}'
remote_write:
- url: "http://graphite-remote-adapter:9201/write"
Cделал relabel метки instance - дефолтно отдается имя хоста (например myserver.test.ru:8080), но точки в графите в имени метрики запрещены, поэтому они заменяются на % (или что-то подобное). Из-за этого трудно построить дашборд (он так и норовит поломаться), поэтому и была сооружена вышеуказанная подмена. В результате label instance будет отдаваться в виде shorthostname_port (myserver_8080).
remote_write - это то, чтобы будем отправлять в другой сервис-прослойку - graphite-remote-adapter. Что это должен быть за сервис в классическом стеке graphite - мне неизвестно, но скорей всего это должен быть graphite-web (могу сильно ошибаться, т.к. начал изучать graphite-based мониторинг тогда, когда от классического graphite осталось только обобщающее слово). В нашем стеке на базе graphite такого сервиса нет, поэтому используется graphite-remote-adapter. Пример конфига graphite-remote-adapter.yml:
web:
listen_address: "0.0.0.0:9201"
telemetry_path: "/metrics"
read:
timeout: 50s
delay: 10s
ignore_error: false
write:
timeout: 1m
graphite:
default_prefix: metrics.minio.
enable_tags: false
write:
carbon_address: 1.1.1.1:2003
carbon_transport: udp
carbon_reconnect_interval: 1m
enable_paths_cache: false
paths_cache_ttl: 10s
Все метрики будут попадать по пути metrics.minio. Cервис имеет небольшой веб-интерфейс, в котором интересна вкладка Simulation:
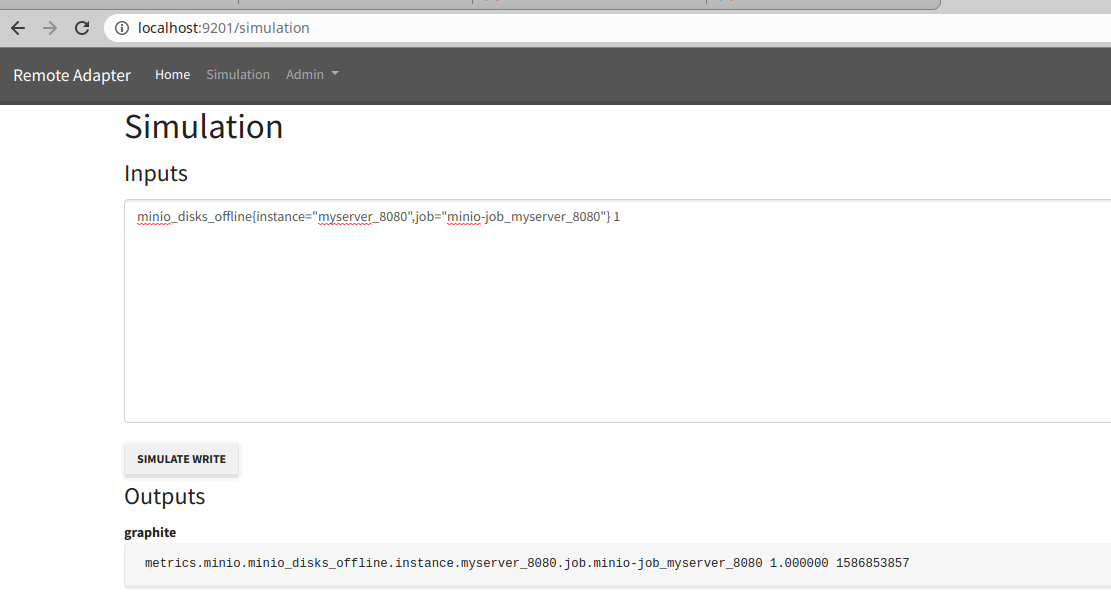
Можно указать метрику из prometheus и увидеть какой она вид примет в graphite.
Все, запускаем prometheus и graphite-remote-adapter, делаем так, чтобы prometheus мог отправлять данные в graphite-remote-adapter, а тот в свою очередь имел сетевой доступ для отправки метрик в graphite.